Lesson 3 — Ethical Principles, Professional Standards, and the Legal Stress Test
Module 2, Unit 2 | Lesson 3 of 3
By the end of this lesson, you will be able to:
- Compare how two leading technology organisations frame responsible AI, and identify where their principles converge and diverge
- Describe the five key ethical principles relevant to AI development — fairness, transparency, accountability, reliability, and privacy — and explain what each means in practice
- Explain who holds accountability when an AI system causes harm, and describe the chain of responsibility from model provider to deploying organisation to individual practitioner
- Demonstrate safe working practice by verifying AI-generated legal information against authoritative sources before using it to inform decisions
- Produce a Legal Compliance Checklist for your project process that clearly identifies what you know, what you do not know, and what further investigation is required
🎬 Microsoft and Google on Responsible AI
Understanding responsible AI requires more than reading regulatory guidance — it means seeing how the organisations that build and deploy AI at scale have chosen to frame their own obligations. The two videos below present Microsoft's and Google's responsible AI frameworks respectively. Together they give you two real-world reference points from major AI platform providers — frameworks you will use in the warm-up reflection to compare, question, and ultimately benchmark against the independent regulatory and academic standards covered in this lesson.
Video 1 — Microsoft: Responsible AI Principles Microsoft Learn, AI-3017 Episode 3 | 10 minutes 17 seconds
Microsoft's video covers the six principles at the centre of their responsible AI framework — fairness, reliability and safety, privacy and security, inclusiveness, transparency, and accountability — and situates them within a practical governance approach that distributes responsibility across the organisation.
Video 2 — Google: Introduction to Responsible AI Google Cloud | 7 minutes 55 seconds
Google's video introduces their three AI principles framework — be socially beneficial, avoid creating or reinforcing unfair bias, and be built and tested for safety — alongside a set of supporting commitments that shape how they approach AI development.
💬 Warm-up reflection — comparing two frameworks
Take ten minutes to think about your initial responses to the three questions below. You do not need to be definitive. The goal is to notice what each framework emphasises and to start forming your own view before the lesson content shapes it.
1. What do the two frameworks have in common? Identify at least two principles or commitments that appear in both, even if they are named differently or structured differently.
2. Where do they differ? Microsoft uses six principles; Google uses three. Is that a meaningful difference in how they think about responsible AI — or a difference in how they have chosen to communicate it? What does the structural choice suggest about each organisation's priorities?
3. Both frameworks come from organisations that are also major AI platform providers. Does that context affect how you read them? What would you want to know from a regulator or an independent body that you cannot get from a company's own principles statement?
💡 There are no right answers here. They are a useful starting point for discussing how principles frameworks function in practice, and how they relate to the legal and regulatory landscape you explored in Lessons 1 and 2.
The five ethical principles in AI
Ethical principles in AI are not abstract philosophy. They are practical commitments — to the people affected by the systems you build, to the organisations that deploy them, and to the profession of AI practice itself. Five principles appear consistently across UK regulatory guidance, professional frameworks, and international standards.
You will probably notice that they overlap with both frameworks you have just watched. That is not a coincidence. These principles have emerged from a broad international conversation about what responsible AI development requires, and the fact that Microsoft, Google, the UK government, and the Alan Turing Institute all arrive at related (though not identical) lists is itself meaningful: it suggests a genuine area of convergence, even where the specific structures differ.
Fairness means that an AI system should not produce outputs that unjustly advantage or disadvantage individuals or groups. This goes beyond legal compliance with the Equality Act: a system can be technically non-discriminatory and still produce outcomes that are unfair in ways that are harder to measure — allocating resources unequally, applying different standards to different groups, or optimising for a metric that benefits some users at the expense of others. Fairness requires actively examining who benefits from a system and who bears its costs.
Transparency means being honest and open about how an AI system works — what it does, what data it uses, and how it arrives at its outputs. Transparency has two audiences: the people affected by AI decisions, who deserve to understand why a decision was made about them, and the people within an organisation who are responsible for the system, who need to understand how it works in order to oversee it meaningfully. A system that functions as a black box — even if it performs well — creates accountability gaps that become critical when something goes wrong.
Accountability means that someone is responsible for the outcomes of an AI system. This is explored in more depth in the next section. The principle is that accountability cannot be delegated to the algorithm. When a system causes harm, the question "the AI did it" is not an answer — it is the beginning of a question about who designed, deployed, authorised, and monitored the system.
Reliability means that an AI system performs as intended, consistently, across the range of inputs and contexts it is expected to encounter. A system that performs well on average but fails unpredictably in specific circumstances — and those circumstances are never disclosed — is not reliable in the meaningful sense. Reliability requires testing, monitoring, and transparency about known limitations.
Privacy — covered in depth across Lessons 1 and 2 — means that AI systems must respect individuals' rights over their personal data and treat information about people with appropriate care. Privacy is not only a legal obligation; it is an ethical commitment to treating people's data as belonging to them, not as a resource to be extracted and used however is convenient.
Key References:
- UK Government's AI principles (DSIT): https://www.gov.uk/government/publications/ai-regulation-a-pro-innovation-approach/white-paper
- Alan Turing Institute — Understanding Artificial Intelligence Ethics and Safety: https://www.turing.ac.uk/research/publications/understanding-artificial-intelligence-ethics-and-safety
- Centre for Data Ethics and Innovation (CDEI) — AI Assurance Roadmap: https://www.gov.uk/government/publications/the-roadmap-to-an-effective-ai-assurance-ecosystem
💬 Reflection
Take the five principles and apply them mentally to the AI system you are designing. Which of the five is most easily satisfied? Which is most difficult? Where fairness is hardest, it is usually because the system will produce different outcomes for different people — and the question of whether those differences are justified is often not a technical question at all.
Transparency in practice: explaining AI outputs
Transparency as a principle is easy to endorse. Transparency in practice is harder.
The core obligation is this: the people affected by an AI-assisted decision should be able to understand, in terms that are meaningful to them, what the system did and why the outcome was what it was. "The algorithm assessed your application" is not a meaningful explanation. Neither is a list of the model's input features.
A meaningful explanation, at the practitioner level, typically covers:
- What the system assessed — what inputs it considered
- What it found — what pattern or signal drove the output
- What the outcome means in concrete terms for the person
- What they can do if they disagree
What this looks like in practice — Demo 1 revisited
In Module 1, Unit 2, you watched a customer feedback workflow in which an AI model classified each piece of feedback as positive or negative, and automatically drafted a follow-up email for any customer whose feedback was marked negative. A human reviewer then approved or rejected each draft before anything was sent.
That workflow is a useful test case for transparency. Suppose a customer later asks: "Why did I receive a personal follow-up after leaving my feedback, when my colleague who submitted feedback at the same time did not?"
A non-transparent answer — the kind that fails the standard — would be:
"Our system automatically identifies customers who may need additional support."
That tells the customer nothing meaningful. It does not explain what was assessed, what was found, or what they can do if they feel the classification was wrong.
A transparent answer — one that meets the standard — would be:
"Your feedback was analysed by an AI tool that assessed the sentiment of your written response and classified it as indicating dissatisfaction. That classification triggered a review process, and a team member read your feedback and the drafted response before deciding to send it. Your colleague's feedback was assessed as positive, so no follow-up was generated. If you believe your feedback was misclassified, or if you have any concerns about how your response was used, you can contact [name/team] to request a review."
Notice what the second explanation does: it names the input (the written feedback), the process (sentiment classification by an AI tool), the human role (a team member reviewed before sending), the outcome for the other person (no negative classification, no follow-up), and the route to challenge. It is specific without being technical.
The same four-part test applies to the practitioner designing the system — before deployment, not after a customer asks. If you cannot draft a transparent explanation for the people your system affects, that is a signal the system is not ready to deploy.
This standard is required by UK GDPR in Article 22 contexts (automated decision-making), and is increasingly expected by regulators across sectors even where Article 22 does not technically apply. Building a system without a clear explanation framework is not just an ethical problem — it is a risk management problem, because the question "can you explain how this decision was made?" will be asked eventually.
Accountability: who is responsible when AI causes harm?
When an AI system causes harm — produces a biased output, makes a wrong decision with significant consequences, or fails in a way that affects people — the question of accountability arises. In practice, accountability in AI systems runs through a chain, and understanding where you sit in that chain is part of what it means to practise responsibly.
Model providers and developers — the organisations that build foundation models or AI tools are responsible for the capabilities and limitations of those tools, and for being transparent about them. If a model has known failure modes, the provider has an obligation to disclose them in documentation.
Deploying organisations — the organisations that integrate AI tools into their workflows are responsible for ensuring those tools are fit for the purposes they are used for, that data protection obligations are met, and that oversight mechanisms are in place. Deploying a tool that the provider has indicated is not suitable for high-stakes employment decisions in a high-stakes employment context is the deploying organisation's liability.
Individual practitioners — you, as the person designing, specifying, or implementing the AI system within your organisation, hold a professional responsibility for the quality of your practice. This is not the same as legal liability in all circumstances — but it is the foundation of what it means to be a professional rather than merely a technical operator. A practitioner who builds a system that they knew might produce discriminatory outputs, and chose not to flag that concern, is not absolved by the fact that a manager approved it.
This chain matters because it is not linear — multiple parties hold accountability simultaneously, and identifying your position in it helps you understand both your obligations and the limits of your authority.
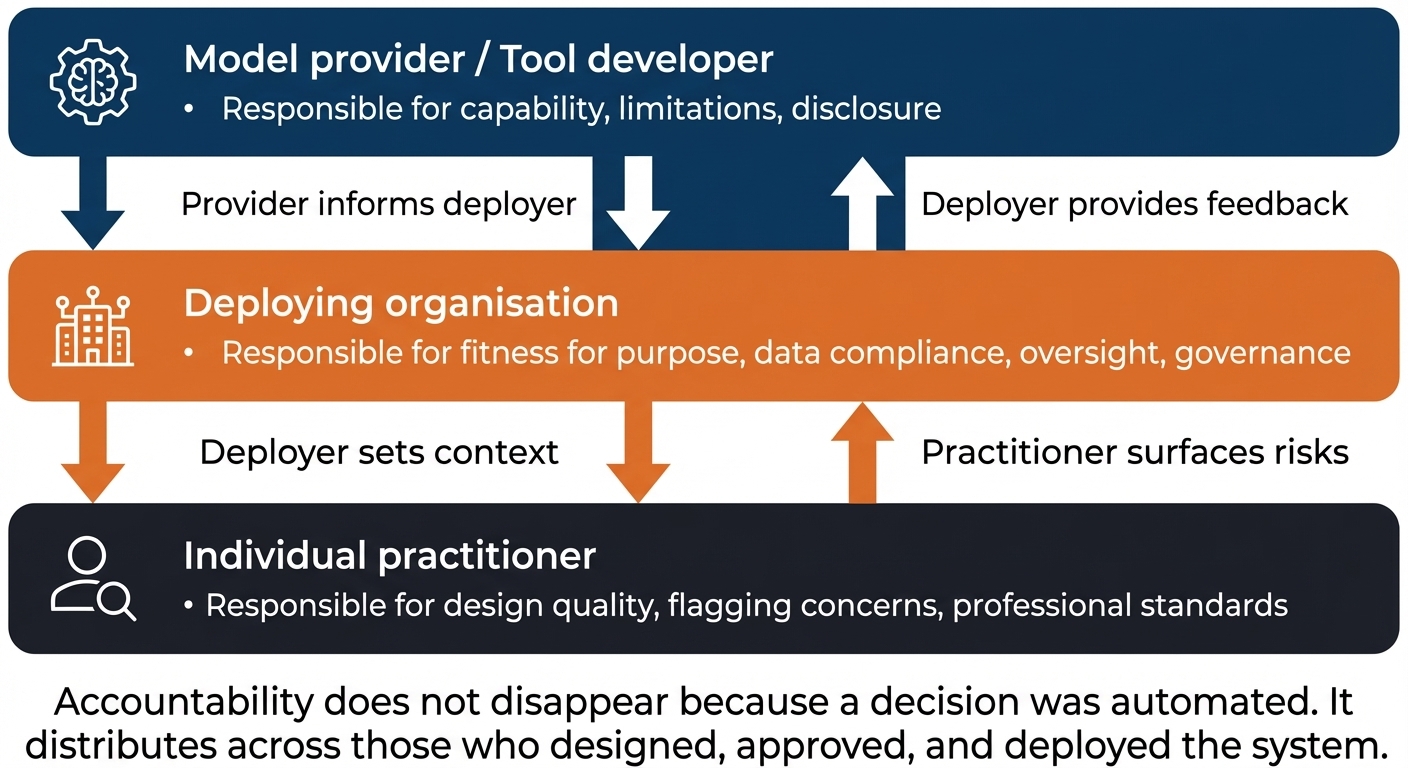
The tricky thing about this chain is that accountability does not flow in one direction and stop. Think of it as overlapping rather than sequential: the model provider is accountable for what the tool is capable of and what they disclosed; the deploying organisation is accountable for whether the tool was appropriate for the context and whether safeguards were in place; you as a practitioner are accountable for the quality of your design and whether you flagged risks you identified. All three levels can be accountable for the same harm. The key practical question for you is: 'What did I know, what did I flag, and what did I do about it?'
Using AI for legal and compliance research: what you need to know
The Legal Stress Test activity in this unit asks you to use a GenAI tool to research legal questions — and then verify whether its answers are accurate. This is a deliberate design choice, and understanding why matters.
GenAI tools can produce legal information that sounds authoritative, is confidently worded, and is wrong. This is not a hypothetical risk — it is well documented. In 2023, US lawyers submitted court filings citing AI-generated case references that did not exist. The cases had plausible names, realistic citations, and were entirely fabricated. The lawyers were sanctioned.
Did you know?
The 2023 case — Mata v. Avianca, Inc. (S.D.N.Y., 1:22-cv-01461) — involved two lawyers who used ChatGPT to research precedents for a personal injury claim. The AI produced six case citations — complete with court names, dates, and docket numbers. None of them existed. When the judge asked for copies of the cited cases, the lawyers could not produce them. Both were fined $5,000 each and required to complete legal education courses on AI use. The case prompted bar associations and law societies across multiple countries — including in the UK — to issue formal guidance on the use of AI in legal practice. It remains one of the most cited examples of why 'AI hallucination' is not just a technical curiosity but a professional liability risk.
The risk in an AI practitioner context is not usually fabricated citations — it is partial accuracy. A GenAI tool asked about Article 22 of UK GDPR may correctly describe the general principle but miss the current ICO interpretive position on what constitutes "meaningful human involvement," or conflate EU GDPR positions (which differ from UK GDPR post-Brexit) with the current UK standard, or describe the law as it stood in 2021 rather than as it is now. Each of these errors, in isolation, sounds credible. Together, they produce advice that could lead to a compliance failure.
The rule for a professional practitioner is straightforward: AI-generated legal information is a starting point for research, not an endpoint. Any legal or regulatory claim that will inform a design decision, a compliance assessment, or a recommendation to a client or employer must be verified against an authoritative primary source — the legislation itself, ICO guidance, or published regulator position — before it is relied upon.
This is exactly what the Legal Stress Test asks you to do.
📝 Activity 1 continued — Section 4: Transparency and Accountability
Complete this final section of your Legal Compliance Checklist now, then compile all four sections for submission.
-
Can you explain, in plain language, how your AI system produces its outputs? Draft two or three sentences you could give to a person affected by one of its decisions — not a technical description, but a meaningful explanation.
-
Who in your organisation is accountable if the system produces a harmful or unfair output? Name the role, not just "the organisation."
-
Where does your role sit in the chain of accountability for this system? What decisions have you made or influenced, and what concerns have you surfaced to whom?
-
Flag: Is there any area of this system's operation that you currently cannot explain clearly? If so, that gap needs to be resolved before deployment.
Reflection
Estimated time: 15 minutes
Look back across all four sections and write a short reflection (100–150 words) answering the following:
- Which questions did you use AI assist for, and which did you answer from your own knowledge?
- What does that pattern tell you about where your legal knowledge is currently strong and where it is still developing?
- What is one specific thing you will check with a colleague, your DPO, HR, or a sector specialist before your project proceeds?
This reflection contributes to your portfolio evidence for S2. It does not need to be long — what matters is that it is honest and specific to your project.
💡 Distinction note: A distinction-level reflection names a concrete next action — a specific person to speak to, a specific question to put to them, and why that conversation matters for your project before deployment.
📝 Activity 2 — Update Your Stakeholder Summary
Estimated time: 20 minutes Add this as a section to your Stakeholder Wellbeing Summary from Unit 1
Now that you have completed the Legal Self-Assessment, return to the Stakeholder Wellbeing Summary you produced in Unit 1 and add a brief Legal Considerations section.
The section should cover:
- The most significant legal consideration your assessment identified for your process. Be specific: name the relevant legislation or principle and explain why it applies.
- Any area where you flagged uncertainty and identified who needs to be involved to resolve it.
- Any legal or regulatory constraint that will affect how your system is designed — and what that means in concrete design terms (for example: "the monitoring element of the workflow needs explicit employee notification before deployment" or "the automated decision step will require a human review gate to comply with Article 22").
KSB coverage — Unit 2
| KSB | Description | Where evidenced |
|---|---|---|
| K2 | Legal and regulatory frameworks including employment rights, equality, and responsible automation, data protection and GDPR. Ethical principles and professional standards in AI development. | Lessons 1, 2, and 3; warm-up reflection; Activity 1 Legal Compliance Checklist |
| S2 | Follow ethical, responsible and safe working practices respecting confidentiality and sensitive organisational matters. | Activity 2 Legal Stress Test — verification and reflection |
| B1 | Work independently and take responsibility to maintain a productive and professional working environment with secure working practices. | Activity 2 (independent research and critical evaluation); Activity 3 |
⏭️ Up next — Unit 3: With your legal and ethical foundations in place, Unit 3 moves into the practice of responsible AI leadership.